







title: V4-V6平台数据迁移介绍

1、 部署简介
1.1、 移环境准备
三层网络
规划网络时,需要注意备端的ip被占用,备端的ip地址被占用了导致虚机恢复失败, 备端没有占位虚机的记录, 所以主端移除资源时, 不会去备端移除资源.
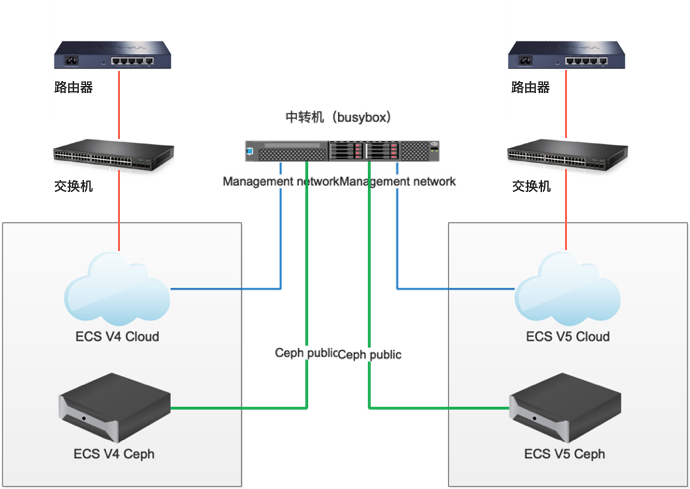
V4-V6平台数据迁移环境设备搭建共五组设备
- 路由器
- 交换机
- 中转机
- ECS 4.0.3 平台(简称 V4平台)
- ECS 5.0.2 平台(简称 V5平台)
环境介绍
需要准备一台中转机,做两边环境访问使用。
分别获取v4和v6环境上的vlan和cidr信息,v4环境登陆roller,在设置-网络中,记录management网络和storagepub网络的cidr和vlan。v6环境登陆ecas,环境配置->网络配置,获取高级网络配置-管理网络和高级网络配置-存储集群业务网络的cidr和vlan ID。并分别在这四个网络的cidr内,选择可用ip作为网关。
中转机配置四个网卡,分别连接V4环境和 V6环境的 management 网络,和Ceph-public 网络。如果网卡对应的交换机端口可以分别访问management和ceph public的vlan,则只需要两个网卡连接两个不同的环境,如果两个环境的management和ceph public的vlan,通过中转机对应的一个交换机口都可以访问,则只需要一个网卡。
在本方案中,例如ip 地址设置如下
V4 management network: 192.168.10.0/24 vlan 100
V4 ceph public: 172.19.10.0/24 vlan 101
V6 management network: 192.168.20.0/24 vlan 200
V6 ceph public: 192.168.30.0/24 vlan 201
中转机配置四个IP
192.168.10.199
172.19.10.199
192.168.20.199
192.168.30.199
四个ip需要在中转机上都添加子设备和设置IP,比如给放行vlan 100能够访问v4管理网的中转机网卡eth0添加vlan 100的子设备,并配置IP
ip link add link eth0 name eth0.100 type vlan id 100 ip link set up dev eth0.100 ip a add 192.168.10.199/24 dev eth0.1002、 中转机准备
2.1、 中转机安装
- 在中转机上安装 CentOS7.4 操作系统。 在安装过程中,将硬盘空间都分配给根目录。
- 配置中转机网络,使中转机能够连接 ECS V4的 ceph public 网络和 management 网络以及 ECS V6的ceph public 网络和 management 网络。
2.2、 Busbox容器安装
研发团队提供了 busybox 容器镜像,通过 busybox 容器可以访问到 v6版本的 ceph 和 openstack api
- 在中转机上安装 docker
yum install -y docker #systemctl start docker - 导入 busybox.tar镜像
docker load < busybox.tar #docker image list
可以通过这个 docker 容器,访问V4,V6两个集群
- 启动容器
docker run -it --network host -v /rbd-store/:/data 1b4293c4a5ef bash
(1)命令中,/rbd-store:/data 指将 host 的/rbd-store 目录挂到容器的/data 目录中,可作为 rbd 导出的临时空间,所需的硬盘空间较大;
(2)1b4293c4a5ef为image id ;
(3)–network host 为指定容器使用 host 网络,是busybox可以同时访问两个集群。
容器启动后,如上图显示。
2.3、 Busybox 配置连接openstack api
(1)在 busybox 容器中,配置域名访问
编辑/etc/hosts 文件,添加如下内容
192.168.20.2 cinder.openstack.svc.cluster.local
192.168.20.2 neutron.openstack.svc.cluster.local
192.168.20.2 heat.openstack.svc.cluster.local
192.168.20.2 aodh.openstack.svc.cluster.local
192.168.20.2 glance.openstack.svc.cluster.local
192.168.20.2 keystone.openstack.svc.cluster.local
192.168.20.2 murano.openstack.svc.cluster.local
192.168.20.2 ceilometer.openstack.svc.cluster.local
192.168.20.2 nova.openstack.svc.cluster.local
192.168.20.2 gnocchi.openstack.svc.cluster.local
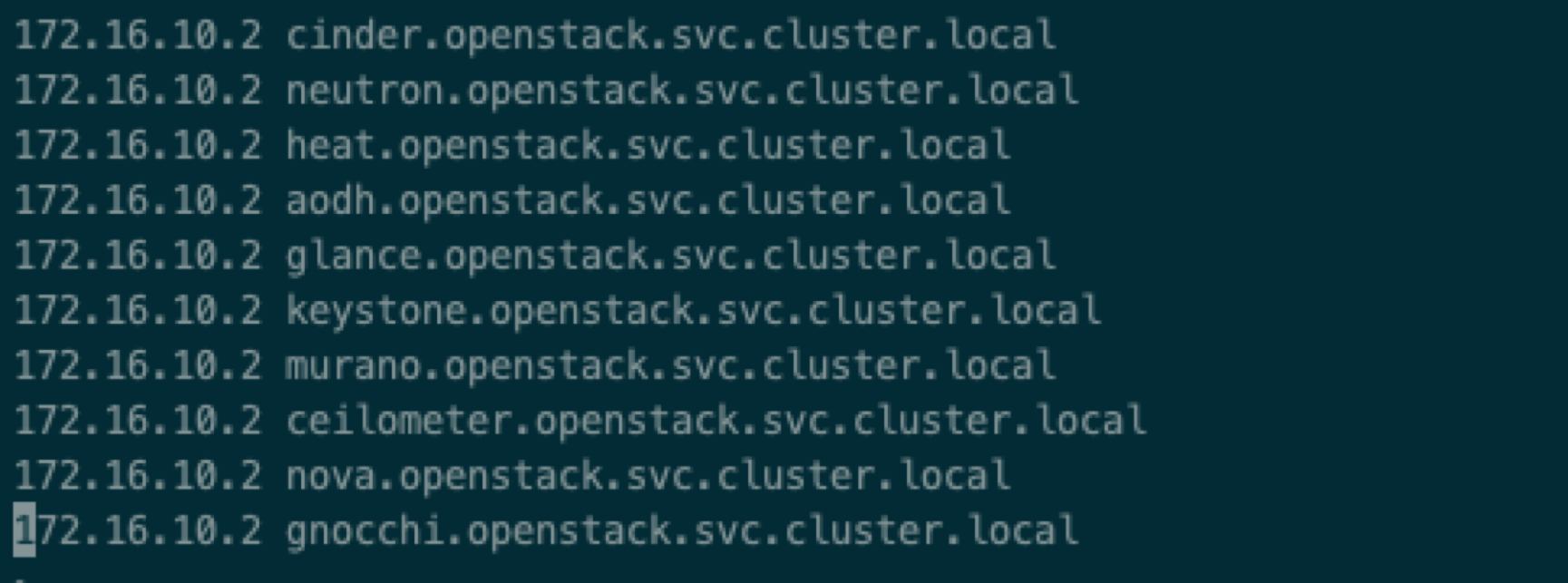
192.168.20.2为 V6s环境的 management 网络 vip。
(2)设置V6环境 openrc 文件
#touch /root/openrc.v6
#vim /root/openrc.v6
#!/bin/sh
for i in `env | grep OS_ | awk -F= '{print $1}'`; do unset $i; done
export OS_TENANT_NAME="admin"
export OS_USERNAME="admin"
export OS_PASSWORD="Admin@ES20!8"
export OS_AUTH_URL='http://keystone.openstack.svc.cluster.local/v2.0'
export OS_AUTH_STRATEGY='keystone'
export OS_REGION_NAME="RegionOne"
export OS_ENDPOINT_TYPE='publicURL'
export OS_INTERFACE='publicURL'
# When neutron client returns non-ascii character and stdout is piped or
# redirected, it would raise an encoding error.
export PYTHONIOENCODING=UTF-8
#touch /root/openrc.v6.domain
#vim /root/openrc.v6.domain
#!/bin/sh
for i in `env | grep OS_|awk -F= '{print $1}'`;do unset $i ;done
for i in CINDER_ENDPOINT_TYPE GLANCE_ENDPOINT_TYPE NOVA_ENDPOINT_TYPE KEYSTONE_ENDPOINT_TYPE NEUTRON_ENDPOINT_TYPE; do unset $i; done
export OS_IDENTITY_API_VERSION=3
export OS_DOMAIN_NAME="Default"
export OS_USER_DOMAIN_NAME="Default"
export OS_USERNAME="admin"
export OS_PASSWORD="Admin@ES20!8"
export OS_AUTH_URL='http://keystone.openstack.svc.cluster.local/v3'
export OS_REGION_NAME="RegionOne"
export OS_ENDPOINT_TYPE='publicURL'
export OS_INTERFACE='publicURL'
export PYTHONIOENCODING=UTF-8- 测试连接 V6环境
source /root/openrc.v6
nova service-list 
- 退出busybox容器,重新进入
source /root/openrc.v6.domain
openstack project list 上面两步都成功输出,说明连接V6环境成功。
(3)设置V4环境 openrc 文件
#touch /root/openrc.v4
#vim /root/openrc.v4
#!/bin/sh
for i in `env | grep OS_ | awk -F= '{print $1}'`; do unset $i; done
export OS_NO_CACHE='true'
export OS_TENANT_NAME='admin'
export OS_USERNAME='admin'
export OS_PASSWORD='admin'
export OS_AUTH_URL='http://192.168.10.2:5000/v2.0/'
export OS_AUTH_STRATEGY='keystone'
export OS_REGION_NAME='RegionOne'
export CINDER_ENDPOINT_TYPE='publicURL'
export GLANCE_ENDPOINT_TYPE='publicURL'
export KEYSTONE_ENDPOINT_TYPE='publicURL'
export NOVA_ENDPOINT_TYPE='publicURL'
export NEUTRON_ENDPOINT_TYPE='publicURL'
# When neutron client returns non-ascii character and stdout is piped or
# redirected, it would raise an encoding error.
export PYTHONIOENCODING=UTF-8192.168.10.2为 V4环境 management vip。
测试连接 V4环境
source /root/openrc.v4 #nova service-list 
成功输出,说明连接V4环境成功。
2.4、 Busybox 配置连接 ceph
(1)配置连接V6 Ceph集群
V6 版本没有配置 ceph 加密,只需要配置 ip 地址即可
#vim /etc/ceph_v6/ceph.conf
[global]
auth_client_required = none
mon_host = 192.168.30.6mon_host 为控制节点 ceph public 网络 ip 地址,只写一个即可。
(2)测试V6连接 ceph
#ceph -c /etc/ceph_v6/ceph.conf -s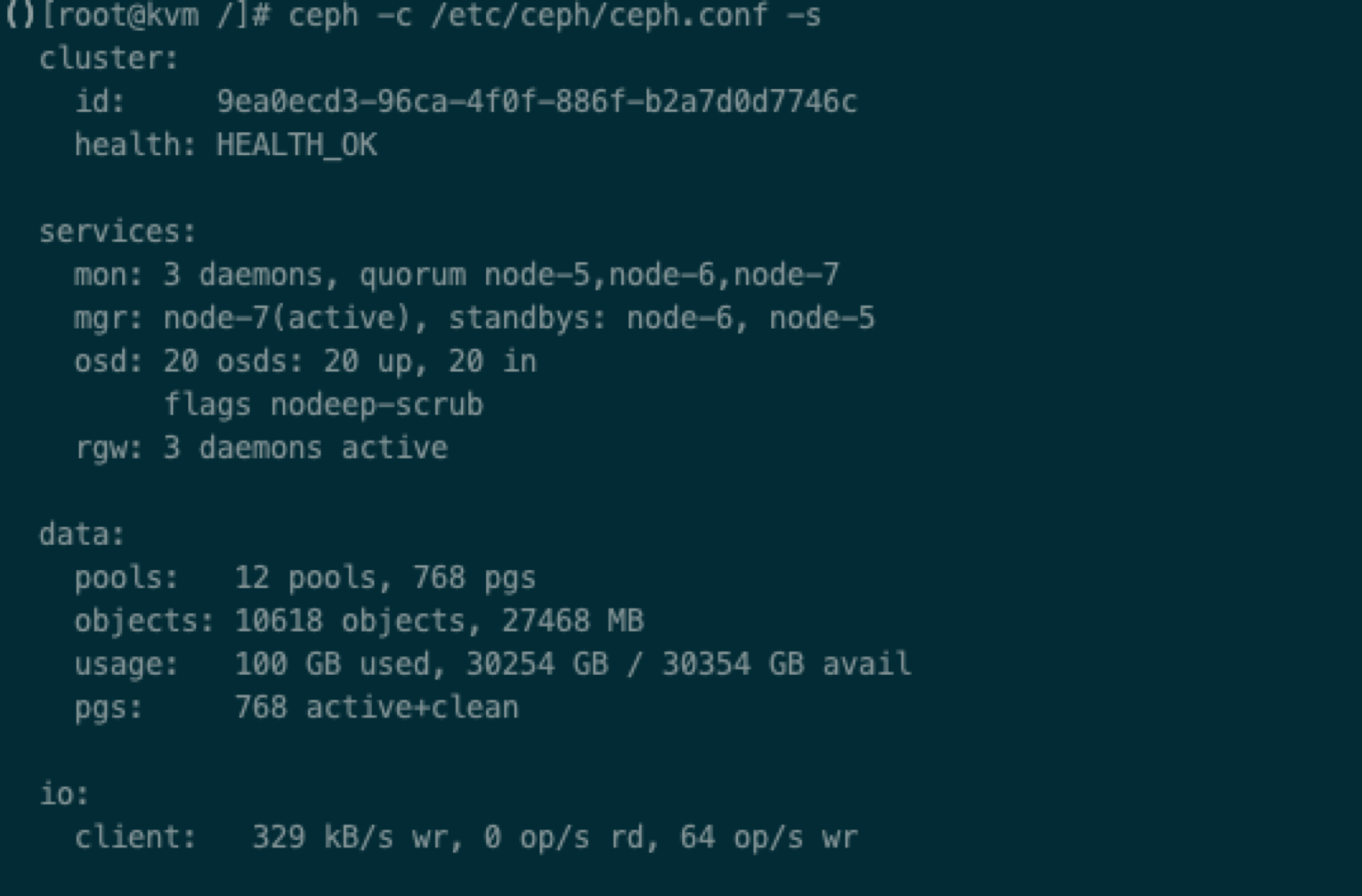
如上图输出,说明连接V6 Ceph 集群成功。
(3)配置连接V4 Ceph集群
V4版本ceph 配置了 cephx 加密,所以需要指定 keyring 访问。
从V4环境控制节点,复制/etc/ceph 目录下,所有文件至中转机 host 系统下
# scp -r 172.18.10.2:/etc/ceph /root/ceph_v4将/root/ceph_v4目录下的所有文件,cp 进 busybox 中 etc/ceph 目录下
# docker cp /root/ceph_v4/ f08235ed7c39:/etc/ceph(4)测试连接 V4集群 ceph
在 docker 中执行:
# ceph -s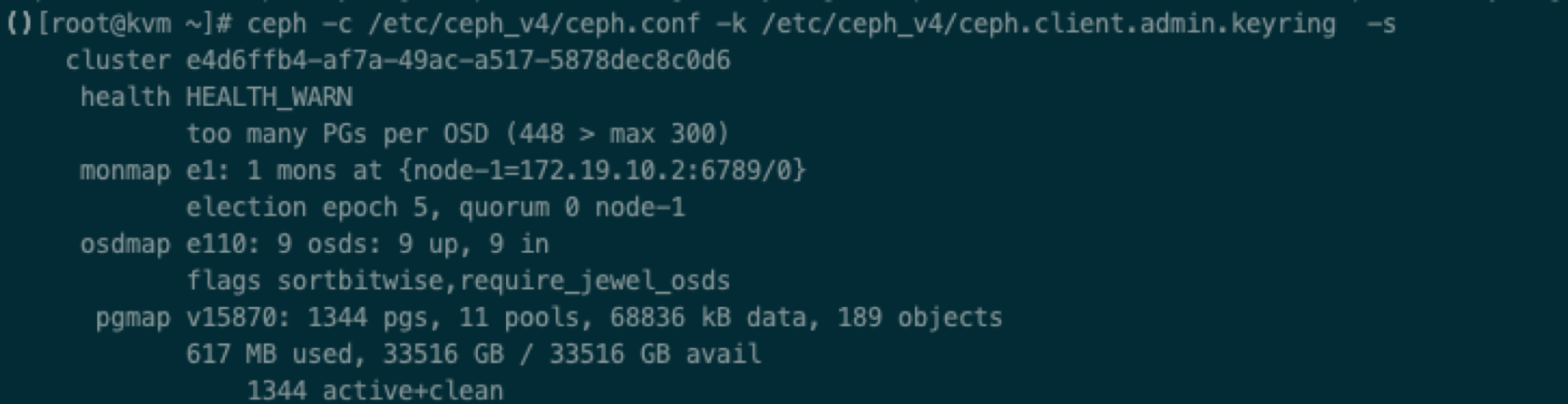
结果输出如上图,说明连接成功。
至此,busybox 已经可以连接V4,V6两个云平台的 openstack api 和 ceph 集群。中转机配置完成。
3、 V4平台安装数据迁移服务并配置
3.1、 解压dr_install_xingyun.tar.gz
在所有控制节点上把dr_install_xingyun.tar.gz拷贝到该目录下,解压:
tar -zxvf dr_install.tar.gz cd dr_install_xingyun
3.2、 安装迁移服务
V4-V6数据迁移过程中,在安装迁移服务之前,需要对V4平台进行变更,来保证V4和V6平台的rabbitmq的相互通信。
3.2.1、 V4平台环境变更
(1) 修改V4环境三个控制节点的oslo.messaging代码
代码路径:/usr/lib/python2.7/site-packages/oslo_messaging/
修改内容如下:
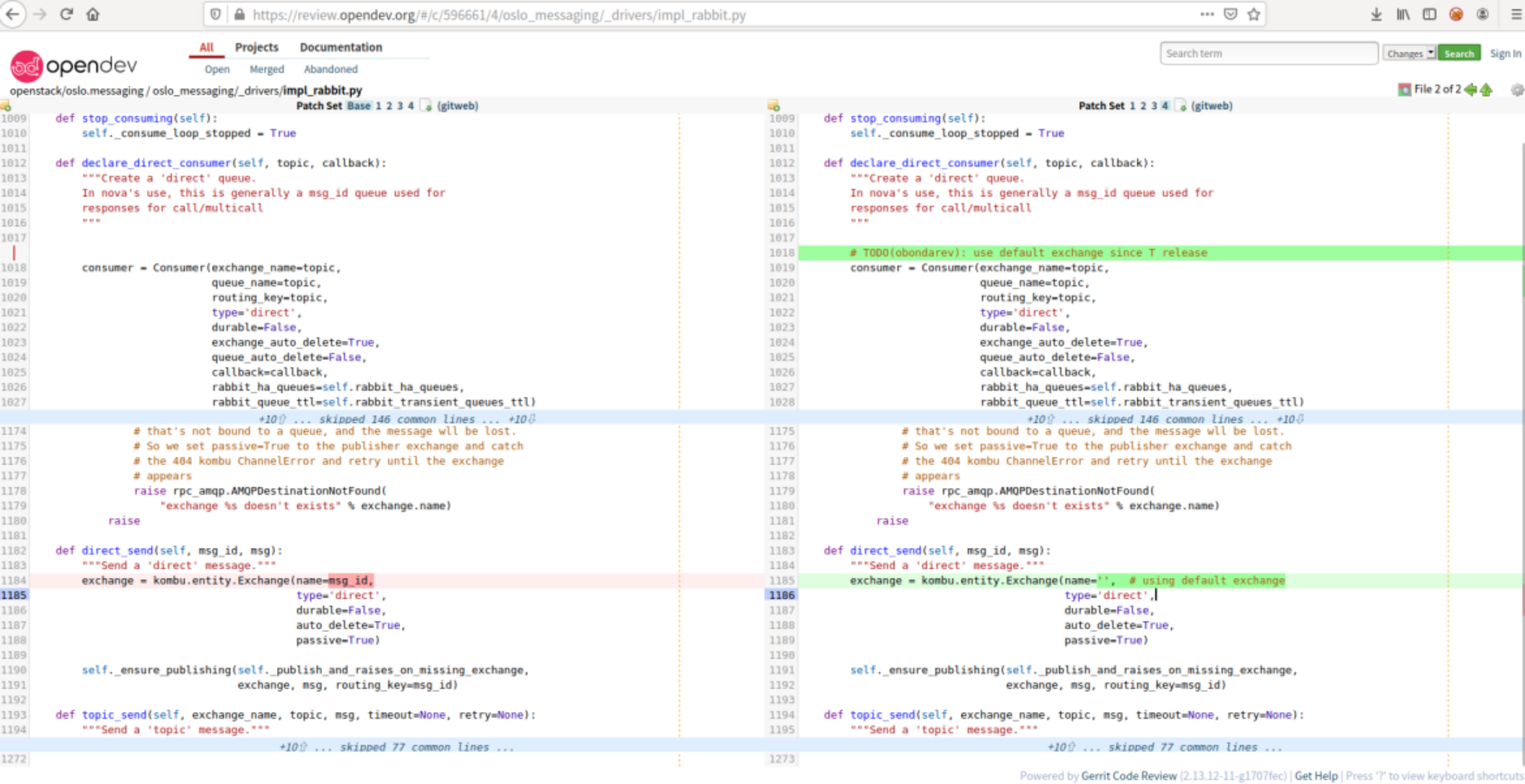
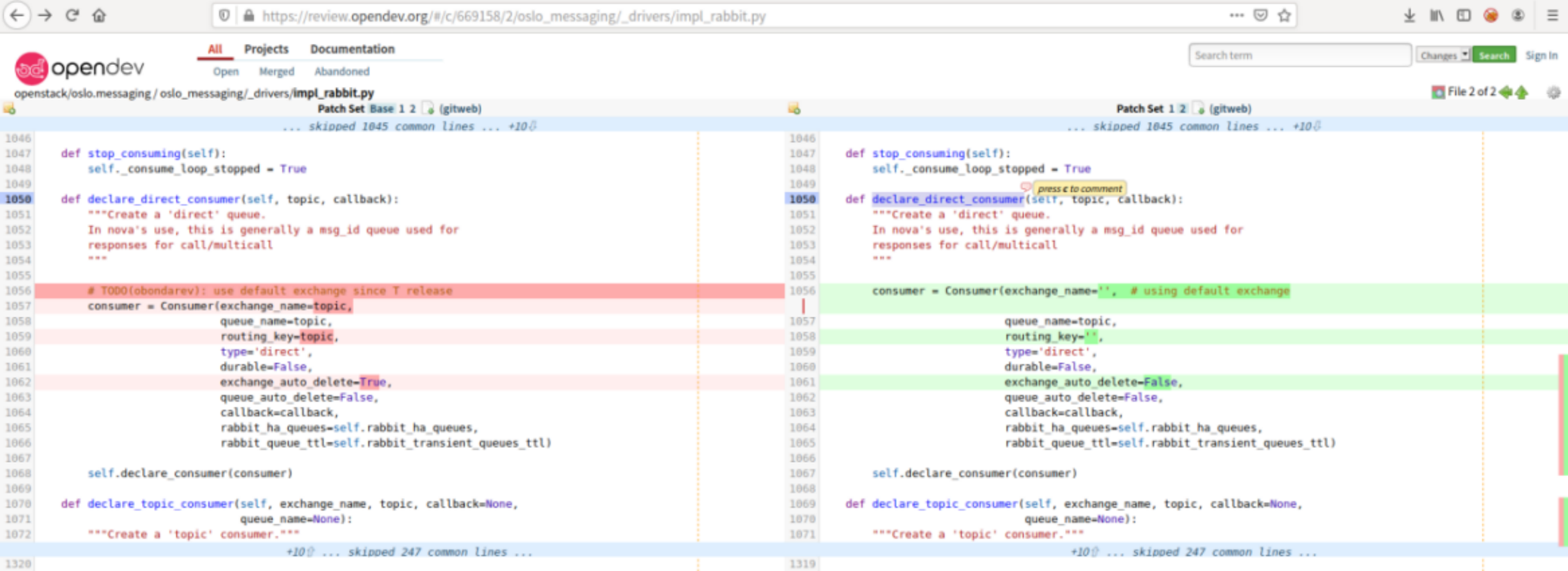
2)重启Rabbitmq
重启rabbitmq是为了让openstack组件重连至rabbitmq,使oslo.messaging代码的改动生效。

重启会导致控制平面有2分钟左右异常,如果在这个过程中要停止和启动集群,请记住关闭节点的顺序:停止的最后一个节点,必须是启动的第一个节点,此节点是主节点。
如果节点启动顺序不懂,则可能会遇到以下问题:
它认为当前主节点不应该是主节点,并删除消息以确保在真正的主节点关闭时没有新消息排队。
重启命令
rabbitmqctl stop :停止rabbitmq
rabbitmq-server restart : 重启rabbitmq3.2.2、 V4平台安装迁移服务
在所有的控制节点执行dr_install.sh安装脚本进行安装dr;
安装脚本中会执行数据库命令创建dr用户,如果需要用户名和密码登录数据库,请在脚本中配置,数据库的用户名和密码:
DB_USER=""
DB_PASSWORD=""如果不需要单独配置数据库的用户名和密码,不需要修改脚本。
执行脚本安装dr
例如:
./dr_install.sh3.2.3、 配置路由(仅限三层网络方案)
在V4端所有控制节点上,配置到对端 management 网络访问路由:
需要保证V4三个控制节点全在线。
ip r add <对端 management 网络 cidr> via <本端 management 网络网关>在V4端所有控制节点和存储节点上,配置到对端ceph-public网络的访问路由:
ip r add <对端ceph-public cidr> via <本端ceph-public网关>
4、V6环境上安装数据保护服务云产品
4.1、数据保护服务云产品license制作(需要专人制作)
交付工程师和系统运维工程师通过发送邮件至数据保护服务云产品的产品经理或研发来申请制作数据保护服务的license,邮件附件中需要包含“V6平台的节点信息(node.data文件)”;
制作完成的license由产品经理或研发通过邮件发送至交付工程师和系统运维工程师。
4.2、 获取并安装数据保护服务云产品
在产品顶部导航栏的【产品与服务/产品与服务管理/云产品市场】中获取云产品,并导入license
在顶部导航栏的【产品与服务/产品与服务管理/已购买云产品】中安装云产品,详细操作说明参见对应的帮助文档。
4.3、 初始化数据保护服务
在顶部导航栏单击【产品与服务/数据保护服务/数据保护服务】菜单项,进入初始化数据保护服务页面。
配置参数,单击保存,保存配置信息。
单击验证完成操作。
参数 获取方法 远端节点配置信息 在V4环境,dr安装包目录执行以下脚本,生成 nodes.data文件
[root@node-2 ~]# cd /root/disaster_recovery/dr_install_20200319130809
[root@node-2 dr_install_20200319130809]# sh v4-nodes.data-generator.sh (第一个参数是br-mgmt第二个参数是br-storagepub)本端管理网络网关 为 V6环境管理网络,访问 V4环境管理网络使用的网关。(本环境中为中转机上设置的地址) 本端存储集群业务网络网关 为 V6环境 ceph-public 网络使用的网关。(本环境中为中转机上设置的地址)。 远端管理网络网关 为 V4环境管理网络,使用的网关。(本环境中为中转机上设置的地址)。 远端存储集群业务网络网关 为 V4环境 ceph-pubilc 网络使用的网关。(本环境中为中转机上设置的地址)
5、 元数据迁移
V4-V6的迁移,分为两部分:云主机/云硬盘元数据的迁移与 ceph 资源池中虚机镜像的迁移。
云主机/云硬盘元数据的迁移即通过数据迁移服务中的迁移处理流程实现,ceph资源池中的虚机镜像需要手动迁移。根据原 V4平台和客户的实际场景需求,将云平台的租户信息,云硬盘类型,SSH key,floating IP等资源在 V6平台上重新创建出来
5.1、 云平台元数据迁移
在 V6云平台上,参照 V4平台和客户需求,需要通过自动化脚本将如下资源自动在V6端创建,若V4端为多级权限,则先需要通过手动创建Domain,project,用户,配额,其他资源仍然通过自动化脚本创建:
| 资源 | 说明 |
|---|---|
| Domain,Project,用户(并分配到租户中) | (1)如果V4环境是多级权限,则权限体系需要手动构建;(2)由于V6版本限制了配额最大值,无法通过脚本直接同步。需要手动配置各个项目配额。 |
| 云硬盘类型 | 脚本仅同步云硬盘类型,对应的 key 和 QoS 规则由于 V4,V6平台不同,需要手动同步。 |
| Vrouter | – |
| 云主机flavor,且flavor ID要与V4一致 | V56端需要提前创建与V4端相同的Flavor,且Flavor ID 一致,否则资源恢复将无法找到对应flavor,导致资源恢复失败。 |
| AZ可用域 | SH Key,防火墙,LB,及未被使用的安全组需要手动同步。 |
为了防止V6端网络恢复后,Vlan ID冲突,建议不要在V6端手动创建网络。
V6平台上恢复的资源如下(v6-v6平台迁移与此一致)
| 资源类型 | 具体资源 | 是否可恢复 | 说明 |
|---|---|---|---|
| 云主机 | flavor | ✅ | – |
| 镜像 | ✅ | – | |
| 描述 | ✅ | – | |
| 所属az | ✅ | 该AZ是创建数据迁移服务的AZ | |
| 网卡 | ✅ | – | |
| 挂载的云硬盘 | ✅ | – | |
| 密码/密码对 | ✅ | 原云主机迁移后仍然可以通过原密码和SSH密钥登录 | |
| 手动添加的metadata | ✅ | – | |
| 指定的hostha | ❌ | – | |
| 主机组 | ❌ | – | |
| 资源层面的user data信息 | ❌ | 但实际user data配置已随着存储恢复 | |
| 云硬盘 | 名称 | ✅ | V4端如果设置了云硬盘QoS,该配置在V6端不生效;由于Linux系统的云主机重启后,挂载的云硬盘盘符可能会发生变化,建议在云主机和云硬盘在加入迁移组前通过UUID指定云硬盘的挂载路径。 |
| 大小 | ✅ | ||
| 描述 | ✅ | ||
| 云硬盘类型 | ✅ | ||
| 云主机绑定的网卡 | 名称 | ✅ | – |
| 绑定的云主机 | ✅ | – | |
| MAC地址 | ✅ | – | |
| 子网 | ✅ | – | |
| IP地址 | ✅ | – | |
| 绑定的安全组 | ✅ | – | |
| allowed-address-pair | ✅ | – | |
| QoS将恢复默认 | ❌ | – | |
| 云主机绑定的网络 | 名称 | ✅ | 若V4端网络指定了AZ,V6端不恢复该AZ信息 |
| 共享 | ✅ | ||
| 云主机绑定的安全组 | 名称 | 远端只能恢复CIDR和当前安全组若V4选择其他安全组,恢复到V6,只能恢复当前安全组 | |
| 描述 | |||
| revision_number | |||
| 安全组规则 | |||
| 云主机绑定的子网 | 名称 | ✅ | 为了保证虚拟机迁移至 V6后 IP 地址不变,V6环境恢复的网络,子网ip 地址与V4版本相同且Vlan ID也相同。 业务网络分为两种情况: a. 三层网络,通过 vrouter 转发出来。 子网恢复时,与 V4平台对应的子网 ip 地址相同,确保虚机迁移至 V6后,地址不变。若V4、V6集群业务网络隔离,V6端恢复网络时,vrouter连接无限制;若云主机业务网络相通,则需要当V4端某一子网下所有虚机都关机、disable DHCP,云主机解绑floating IP、断开路由器后,才能在V6端将自动恢复的子网enable DHCP、绑定vrouter,设置网关,为云主机绑定floating IP。 b. 二层直通网络。 这种情况下,要确保 V6平台创建的网络与 V4平台对应的网络 Vlan 相同,子网 ip 地址相同。为了防止在V5端恢复网络时出现 dhcp 地址冲突的现象,默认情况下V5端恢复的网络将disable DHCP,当V4端该网络下虚机全部关机、disable DHCP后,才能在V6端重新enable DHCP。 用户如果需要测试恢复后的虚机能否通过开机V6的云主机,可以通过为云主机更换IP的方式来访问是否能ping通;V6恢复网络后,默认关闭DHCP,提醒用户不在这个网络下手动创建虚机,否则会占用DHCP地址。 在中转机执行 #source openrc.v4 #neutron port-list #找到目标网络的 dhcp port uuid # neutron port-update –fixed-ip subnet_id=SUBNET, ip_address=IP_ADDR #将 dhcp 地址更新一个临时地址 1、V5平台网络恢复后,默认disable DHCP,防止DHCP server ip 冲突。 2、V5端恢复的网络Vlan ID默认与V4端一致,但若该Vlan ID在V5端已被占用,则会随机使用一个Vlan ID。 3、不支持IPV6 |
| CIDR | ✅ | ||
| 地址池 | ✅ | ||
| DNS服务器 | ✅ | ||
| 主机路由 | ✅ | ||
| enable_dhcp | ✅ | ||
| 网关地址 | ✅ | ||
| 网络ID | ✅ | ||
| IP版本 | ✅ |
5.2、 使用数据保护服务迁移云主机/云硬盘元数据
在创建服务前请务必确认v6端配额满足迁移资源的要求,若配额不足,则会导致资源恢复失败。
5.2.1、 创建数据保护服务
在V4环境中创建数据保护服务,首先需要在V6端获取数据迁移密钥,此时返回V4端数据保护服务页面,点击创建数据保护服务,输入名称,密钥,验证通过后,选择可用域。
如果在迁移过程中,需要修改v6端的可用域,可以通过修改v4端dr数据库connection表中的rmt_az字段为v6端新的可用域名称即可。
不要通过删除数据迁移服务重新创建的方式修改v6端的可用域,这样会导致同步过去的镜像无法使用问题(ECS-3972)。—–作为疑难问题
5.2.2、 虚拟机镜像迁移
数据迁移服务能够实现系统盘和云硬盘的迁移,但虚机镜像仍然需要从 V4 Ceph 集群迁移至 V6 ceph 集群 。虚机镜像数据在ceph 集群的compute 池中 。
将dr项目的镜像迁移脚本(dr/scripts/v4-v6/image_migrate.py)拷贝至busybox的/root目录中,修改该脚本的执行权限
chmod 777 /root/image_migrate.py之后执行
./image_migrate.py --migrate命令开始执行镜像的迁移,会把所有v4端的镜像都迁移到v5端,等待该脚本执行完毕。
也可以指定镜像列表文件,选择性的迁移镜像:
./image_migrate.py --migrate --file ./migrate_images.json在migrate_images.json文件中添加需要迁移的镜像id
脚本执行完毕后会将迁移的结果保存在/tmp/automated_migration_result.txt文件中方便查看。
该脚本支持幂等操作,可以重复执行。
5.2.3、 创建数据保护组
服务创建成功后,进入控制台-数据保护组。
在保护组页面中,点击创建保护组,输入名称,选择数据迁移服务,设置当前保护组为主保护组,输入V6端需要迁移项目的ID(在V5端权限管理中查看拷贝项目ID)。
保护组创建成功且状态切换至关联成功后,前往V6端对应项目的迁移组中查看是否同步创建了备保护组,且状态为关联成功。
需要首先在admin创建迁移组,新建一个虚机,挂上所有的share net,通过迁移的方式把share_net首先进行迁移。其他非admin的project没有迁移share_net的权限
5.2.4、 保护组内添加资源(云主机/云硬盘)
确认后,在V4端保护组页面,点击页面中的某个保护组,进入保护组详情页面,点击添加资源。
在添加资源弹窗中,根据可用域和网络过滤当前项目中的云主机和云硬盘,输入对端项目管理员用户名密码,完成资源添加。建议一个网络下的资源添加在一个迁移组中,便于资源恢复。
资源添加完成后,在保护组组页面,点击开始同步,此时等待数据同步,迁移组详情页面中查看数据同步进度。数据同步期间主端迁移组中资源仍然可以开机/挂载并提供业务能力。
(1)V4端资源添加进保护组后,将不能再修改该资源的元数据(网卡、安全组、安全组规则、密码、SSH Key等。)。若需要修改,请先移除保护组并且删除V6端自动创建的资源,否则,该部分修改的元数据将无法同步到V6端。V6端资源恢复时的元数据将与刚加入保护组时保持一致。
(2)保护组一旦开启同步后,如果中止同步将清空已同步的数据。请慎重中止同步操作。如果同步开始,保护组中如果有资源处于,初始化同步状态,此时停止同步会报错。等到初始化同步完成后,可以进行停止同步。
(3)若数据传输占用带宽太多,影响集群业务正常使用,可以在V6端设置数据同步的QoS带宽。
(4)数据保护服务恢复时只能指定一个AZ,若需要恢复到V6端不同AZ上,需要在资源同步后,删除并创建新的数据保护服务,指定新的AZ;
(5)V4-V6迁移时,由于V4中云主机和镜像绑定,因此迁移时也会同时迁移该部分镜像,但这部分迁移到V6端的镜像无法在界面上资源化管理,因此无法被删除。(可通过脚本解决)
(6)若主保护组移除资源后,备端未移除,此时若该资源再次加入到此迁移组内,则会利旧原有未被移除资源,但若是添加到不同迁移组内,则不会利旧资源。
(7)V6端回收站中的云主机占用IP可能导致添加资源失败,注意V4端迁移的云主机IP在V6端没有从回收站删除,开始同步会失败。
资源添加失败的原因—疑难问题解答
其他项目组中云主机和云硬盘资源参考如上
一个迁移组中资源添加个数没有限制,但数据同步时,对于没有开启同步前所产生的数据会通过快照进行同步,快照同时同步传输限制为5个。根据资源的实际大小,结合环境带宽压力,控制同步的迁移组内的资源个数以及迁移组个数。
5.2.5、 迁移处理
迁移组中数据同步后,将V4环境中保护组中的云主机关机,云硬盘挂载的云主机不在保护组中的云硬盘需要卸载,随后在V6环境中,选中该保护组,点击迁移处理。
若V4端云主机不关机,或云硬盘不卸载,当迁移处理时如果有数据写入,则该部分数据将会丢失。
为了保证两端数据一致性再处理,需要保证在V4端关机后,同步剩余项在至少1分钟内都是0。因为剩余项是每30秒更新一次,所以当第一次显示为0,此时若又有数据写入但是剩余项没有更新,会导致数据不一致风险,资源处于初始化同步状态时,迁移处理会无法成功。
如果是虚机挂载云盘的情况,在资源列表中云盘在虚机的二级列表中,需要点击虚机资源后面的箭头,展开云盘列表查看虚机资源和虚机资源的同步进度剩余项都要为0
迁移处理成功后,此时在V6端将云主机开机,云硬盘会自动挂载。此时您可以查看一下,恢复后的云主机/云硬盘与原主端的云主机/云硬盘的内容是否一致。
迁移成功后,推荐的处理流程:
(1)迁移处理后,需要先在v4端停止同步
(2)停止同步后,要在v6端删除迁移组。
(3)v6删除后,最后删除v4的迁移组。
5.2.6、 迁移处理失败解决办法
- 当V6端迁移处理失败时,您可以在V6端记录迁移处理失败的资源项,删除迁移组后在资源管理页面中将处理失败的资源删除。
- 随后在V4端选中该迁移组中止同步,删除迁移组。
- 在V4端找到对应处理失败的资源重新添加到新的迁移组中,再次执行开始同步操作。
- 剩余操作步骤如上.
5.3、 云主机数据验证
启动云主机,确认系统可以正常启动,查看数据是否完整。
云主机启动后,登陆密码与方式和原虚机一致。

6、业务切换
至此,虚机数据已经完全迁移至 V6平台。 V4平台虚机处于关机状态,V6平台虚机处于启动状态,虚机所关联的网络、子网、网卡、安全组也在迁移处理时被一并被恢复。因此,接下来需要检验V6端网络状态与V4端是否一致,以及为资源挂载Floating IP。
6.1、 网络切换
- V6 端已恢复的网络手动开启DHCP
- 手动开机V6端的虚机
- 检验云主机网卡上的安全组以及安全组规则是否与V4端一致。如果不一致,请手动在V6平台上修改。
由于V4版本支持安全组规则–远端设置选择CIDR/当前安全组/其他安全组,但V6版本中只支持CIDR和当前安全组,因此对于在V4端安全组规则选择为其他安全组的,需要用户重新配置安全组规则。
- 如有需要,将网络绑定路由器,设置网关,为云主机挂载 floatingIP
- 验证网络是否正常。
至此,虚拟机迁移成功。
由于原虚机还在 V4平台上没有删除, 所以务必确保 V4平台虚拟机处于关机状态。 或者记录好 ip 地址与 mac 地址,便于回退。将原虚机网络断开。
7、 验证与清理
7.1、 业务验证
虚机迁移完成后,由业务部门确认虚机运行正常,业务正常启动。 在此期间中,原 V4环境不要删除,便于回滚。
7.2、 数据清理
7.2.1、 镜像迁移服务资源清理
当某个迁移组中资源确认迁移至V6端后,请在V4端对该迁移组进行中止同步操作,避免备份数据继续在本地写入。同时您可以在V6端将已经同步完的迁移组进行删除操作。
将dr项目的镜像迁移脚本(dr/scripts/v4-v5/image_migrate.py)拷贝至busybox的/root目录中,修改该脚本的执行权限
chmod 777 /root/image_migrate.py之后执行
./image_migrate.py --disable命令开始执行镜像迁移完成后的清理工作,等待该脚本执行完毕。
脚本执行完毕后会将清理的结果保存在/tmp/automated_migration_disable_result.txt文件中方便查看。
该脚本支持幂等操作,可以重复执行。
7.2.2、 数据迁移服务资源清理
当V6端所有的group都删除并且镜像都disable后,跳转至数据迁移服务页面,选择数据迁移服务进行删除。至此所有数据迁移服务创建的相关连接数据都将清除。
迁移组中的资源清理仅会清理同步的数据块,不影响资源运行。
8、回滚方案
由于 V4平台没有进行修改,如果迁移后,遇到虚机无法启动,业务无法正常运行等问题。直接关闭虚拟机,将 V4平台上虚机启动即可回滚。


